Projektbeschreibung
Kaum ein Thema des digitalen Wandels wird aktuell so kontrovers diskutiert wie das der Künstlichen Intelligenz (KI). Die zugrundeliegenden Technologien (z.B. Gesichts- und Spracherkennung) werden dabei höchst unterschiedlich verwendet und bewertet.
Wissenschaftlerinnen und Wissenschaftler des Ludwig Forum Aachen im Verbund mit dem HMKV Hartware MedienKunstVerein in Dortmund möchten die Entwicklungen von KI begleiten, kritisch hinterfragen und die Technologie im Hinblick auf eine mögliche Anwendung in der Museumspraxis untersuchen. Im Zentrum steht die Frage, wie eine KI zum Zweck der Strukturierung von Daten im Prozess des (digitalen) Kuratierens und der künstlerischen Produktion eingesetzt werden kann. Welche Wege der Kollaboration zwischen KI-Systemen und Expertinnen sowie Experten sind denkbar und können dazu beitragen, explorative Recherchen zu ermöglichen? Werden Muster, Zusammenhänge und Assoziationen in Daten erkennbar, die für den Menschen in dieser Form nicht ersichtlich sind?
KI in der Museumspraxis
Gemeinsam mit dem Visual Computing Institute der RWTH Aachen University (externer Link, öffnet neues Fenster) als Digitalem Partner entwickelt das Team von "Training the Archive" eine Anwendung, die hilft, enorme Informationsmengen in digitalen Archiven, sogenannte Big Data, zu strukturieren und für Entscheidungen vorzubereiten. Das Projekt möchte das Potential von maschinellem Lernen erschließen und ein funktionsfähiges Verfahren hervorbringen, mit dessen Hilfe Muster und Zusammenhänge zwischen Kunstwerken in musealen Sammlungen für Kuratorinnen und Kuratoren sichtbar gemacht werden können.
Grundlagenforschung zu digitalen Praktiken des Kuratierens
Während der Software-Entwicklung bezieht das Projekt internationale Kuratorinnen und Künstler mit ihren jeweiligen Expertisen ein und befragt sie zu ihrem Umgang mit Daten und Rechercheprozessen. Parallel zur Programmierarbeit wird damit Grundlagenforschung zu digitalen Praktiken des Kuratierens und der künstlerischen Produktion betrieben. Gemeinsam wird ein Verfahren erarbeitet, das hilft, digitale Archive – wie künftig auch die Sammlung des Ludwig Forum Aachen – fachlich neu zu erschließen. Dabei wird ein spielerischer Zugang zu den Werken des Hauses auch für das Publikum denkbar.
Dokumentation und Nachnutzung
Die Ergebnisse des Forschungsprojektes werden kontinuierlich in Working Papers (externer Link, öffnet neues Fenster) auf dem Blog des Ludwig Forum Aachen (externer Link, öffnet neues Fenster) und im Code auf GitHub (externer Link, öffnet neues Fenster) veröffentlicht. Bei der Umsetzung haben sich die Verbundpartner für einen Open-Source-Ansatz entschieden, um Fortschritte direkt für interessierte Kunst- und Kultureinrichtungen und die breite Öffentlichkeit zugänglich zu machen. Für den fachlichen Austausch ist ein Symposium mit internationalen Expertinnen und Experten Ende 2022 geplant.
Ein Verbundprojekt des Ludwig Forum für Internationale Kunst Aachen und des HMKV Hartware Medien KunstVerein Dortmund. Gefördert mit bis zu 704.000 Euro.
Kann Künstliche Intelligenz kuratieren? Interviews mit Expert:innen

Ihre Cookie-Einstellungen haben dieses Video blockiert.

Ihre Cookie-Einstellungen haben dieses Video blockiert.
Social Media
#TrainingtheArchive
Termine
Aktuell keine bevorstehenden Termine
Kontakt
Ludwig Forum für Internationale Kunst
Jülicher Straße 97–109
52070 Aachen
http://ludwigforum.de (externer Link, öffnet neues Fenster)
HMKV Hartware MedienKunstVerein
im Dortmunder U, Ebene 3
Leonie-Reygers-Terrasse
44137 Dortmund
https://hmkv.de (externer Link, öffnet neues Fenster)
Training the Archive
Unsere Projektbeschreibung
Training the Archive lotet die Möglichkeiten & Risiken von KI für die automatisierte Strukturierung von musealen Sammlungsdaten zur Unterstützung der kuratorischen Praxis aus.
Unsere Projektziele (2020), geteilt auf Twitter / X
Unsere Ziele in a nutshell: 1) Die „Curator’s Machine“ entwickeln, die es ermöglicht, frei & komfortabel Museumssammlungen zu durchsuchen 2) Durch Forschung & Interviews das Thema KI beleuchten und auf Grenzen hinweisen Lasst uns dazu austauschen und in einen Dialog kommen!
Illustration unseres Konzepts

Erklärung zu den Prototypen
Die „Curator’s Machine“ entwickelte sich aus Experimenten mit visuellen Clustering-Algorithmen, über multimodale Modelle wie CLIP, hin zu einer Software mit direkter Mensch-Maschine-Interaktion.
Erster Prototyp: Visuelle Clustering-Algorithmen

Zweiter Prototyp: Versuch der Kurator*innen-Beteiligung

Dritter Prototyp: Integration des multimodalen Modells CLIP

Vierter Prototyp: Frühe Version der "Art Search"

Skizze des späteren Interfaces
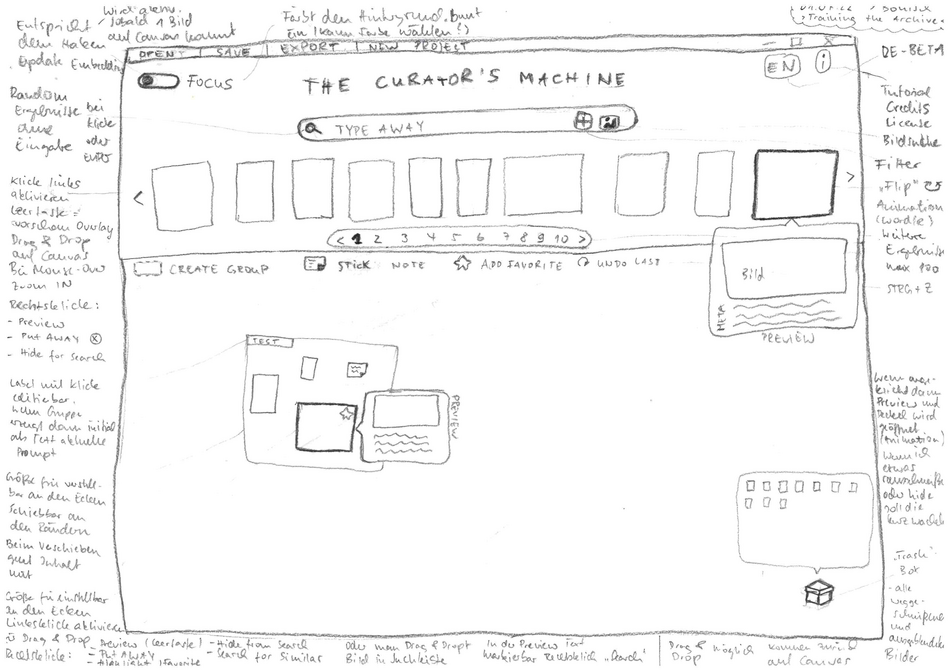
Die finale "Curator's Machine" im Einsatz

Ihre Cookie-Einstellungen haben dieses Video blockiert.
Unsere Vermittlungsformate
Über Formate wie Working Papers, eine Konferenz oder Interviews machen wir unsere Fortschritte für interessierte Kunst- und Kultureinrichtungen und die breite Öffentlichkeit zugänglich und regen zum fachlichen Austausch an.
Unser Output im Detail

Die veröffentlichten Working Papers auf einen Blick

Playlist der geführten Video-Interviews mit Expert*innen

Unsere Konferenz in vollem Gange

Unser preisgekröntes Konferenzplakat

Im Labor im Ludwig Forum erfährt man über das Projekt

Ausstellungsansicht des Labors

Startseite des Projekt-Blogs

Unser Buch im Entwurf
